
This article explains what is SQL and why is it a powerful tool for Impact Measurement and Impact Data Analytics, as well as introduce some fundamental concepts.
What is SQL?
SQL stands for Structured Query Language. (You can pronounce it either as "S.Q.L." or as "sequel".) This language is used to access and modify data that follows a specific structure and maintains a clear relationship to other data in the database.
As an example, let's imagine we have access to a packaging materials store's database. And this is one table that shows a list of their products and details about those products:
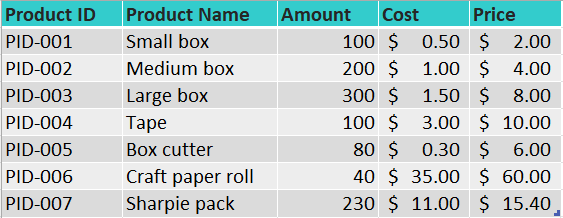
We can observe that the structure of the data is very simple, it just has some columns with titles (or headers) in the first row, and the next rows just show the data vertically.
We can also notice that the information in each cell is related to the information in all the columns for the same row, for instance, a Small box has a product ID of PID-001, there's an inventory amount of 100 small boxes, with a cost of $0.50 and a sales price of $2.00.
Another table in this store's database shows the vendors for each product as such: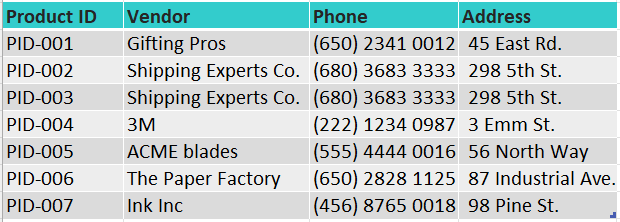
This table relates to the previous one through the first column. For instance, we can tell from looking at the Product ID column that the Small Box (PID-001) is sold by Gifting Pros, whose phone is (650) 2341 0012, and are located at 45 East Rd. Thus, by setting a Product ID for each product in the catalog, they can make connections between different data and keep the relationship across a series of tables, which can be then call a "relational database".
In small databases, we can manually going from table to table, to get some specific information about one product e.g. "What's the address for the vendor or Tape?", where you would have to first go to the Products table to look for the product ID for Tape, and then check the Vendors table to look for the address for PID-004's vendor. But with larger tables with hundreds to thousands of records, SQL helps us to find that information in a matter of an instant as long as you know how to ask through an "structured query" such as:
SQL Query:
SELECT vendors.address -- (find the address)
FROM store.vendors -- (from the vendor table)
INNER JOIN store.products -- (by looking in the product list)
ON vendors.productid=products.product.id -- (for matching product IDs)
WHERE products.productname="Tape" -- (where the product name is "Tape")
Result:
3 Emm St.
For this example, it might take the same amount of time to manually look for the address and to write the necessary query, but when you are working with thousands of records it can become a real hassle to find what you are looking for.
How does SQL relate to IMM?
To do Impact Measurement and Management (IMM) successfully, we need to have access to our impact data to be able to complete the "measurement" step. Again, when we have small tables such as the Packing Material Store example, then it's easy to apply manual or even Excel formulas to calculate our metrics. But when our programs scale, and we collect frequent data on our volunteers, program activities and our stakeholders, it gets harder to keep using the same method each month or each quarter. For example: "What's the percentage of teenagers within our stakeholders?" or "What's the percentual monthly increase of the average GPA within each age group of stakeholders after enrolling in our program?".
This is where fields like data analytics and languages like SQL can help us get more insights, in-depth analysis and forecasts for our programs, while also reducing the monthly, quarterly or yearly workload for our Impact team, as most of these analysis can be saved and updated automatically once they have been created.
What's more, tools for IMM like Impact Cloud, that implement SQL, can allow you to combine several sources of data, many tables, and keep track of those relationships for your programs all in one place, and without the need for a tech team to be able set up and maintain your own database.
Do you need to be proficient at SQL to do IMM?
TLRD: "Not proficient. But becoming familiar with the basics can go a long way in your IMM goals."
Tools like Impact Cloud allow much of the analysis to be performed by selecting from dropdowns and clicking buttons only. But behind the scenes, everything is done with SQL, as keeping track of the relationships across your organization's data is necessary to be able to compute metrics from large databases.
But to be able to compute more advanced metrics, and perform more in-depth analysis that will provide actual insights on what is working and not working within your programs, and to truly be able to quantify your impact to pitch to funders, then becoming familiar with the basics of SQL can exponentially increase your probability of success.
How can I learn the basics of SQL for IMM?
Conveniently, we have created a set of articles that go through the fundamentals of what is needed for you to learn the basic concepts of SQL (more accurately, postgreSQL, which is the specific version of SQL that Impact Cloud implements).
Prerequisites of Data Manipulation
And also a set of articles covering practical examples of how to exploit the SQL capability of Impact Cloud to fit particular scenarios of analysis that your organization could need.
Apart from these SQL-related topics, we have a library of help articles on all the other subjects of how to navigate around Impact Cloud to do all the basic stuff.
Basic Terminology
Now, let's become familiar with several of the terms that we mention in this article and that will be used frequently.
Database : Each database is identified by a name. It consists of number of tables, indexes, schemas etc. For eg. OutcomeDB, DemoSopact etc.
Schema : Each schema is identified by a name. It is a logical grouping of database objects, such as tables, indexes etc. Each Database can many schemas. Schema can therefore be thought of as a folder within the main folder Database. It is an useful way to handle database security administration and access privileges for various applications. eg. public, gc_demo etc.
Tables : Each table is identified by a name. Registration system, for instance. It is made up of rows called Records and a number of columns called fields that are related to one another. Tables are also referred to as datasets. They are used interchangeably.
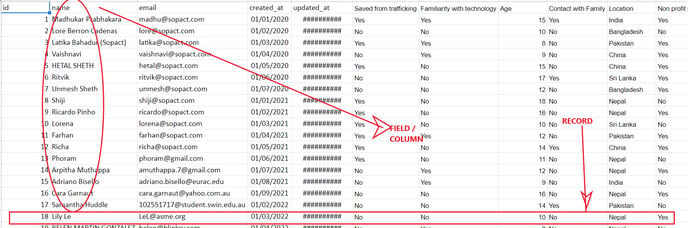
Record or Entry : Each individual entry in a table is referred to as a row. For instance, the aforementioned "Registration system" table contains 35 records. In a table, a record is a horizontal entity. A string of data matching each column field across the top will be present in each record row. For instance, in a "Registration System," each "Registration System Record" would have one row of information including the user's ID, name, email address, age, and other details.
Fields : In a table, it is a vertical entity that holds all the data pertaining to a particular field. Every field in the table is maintained with specific information. In the aforementioned example, the "Registration system" fields include id, name, email, age, etc. as shown above Each field has to be defined into several character types, such as Text, Date, Number, to name just a few. The terms Fields and Columns are used alternatively.